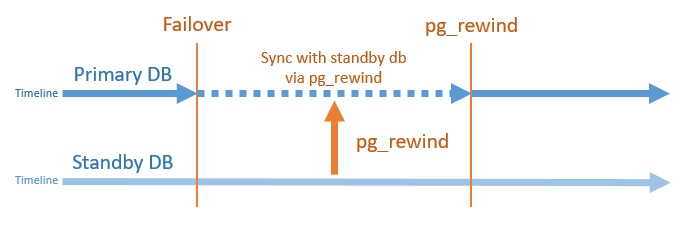
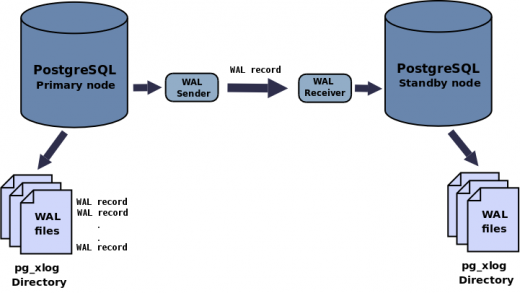
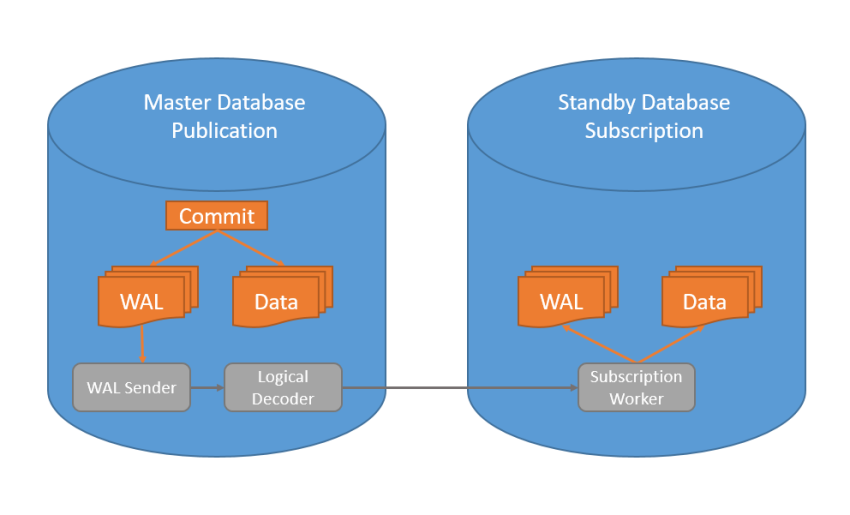
With PostgreSQL 15 version, logical replication became applicable by filtering on the tables by column and row. In this way, replication can be made in the desired columns and rows in the tables. Logical Replication wal_level=logical For logical replication, the wal_level parameter must be logical in the postgresql.conf file . By default, the value of wal_level is replica . The replica value provides the necessary wal files for streaming…
 Follow
Follow